If your GTM agent is built on generic RAG, it can retrieve the right-looking answer but make the wrong decision.
RAG became ubiquitous because it solved a real problem with early AI systems. When ChatGPT launched, AI models had small context windows, which precluded giving models direct access to full documents. RAG provided a way to look up snippets of information and paste it into context.
Nonetheless, it is hard to implement RAG well. RAG can easily pull stale positioning or miss nuance, such as mixing up a current motion as SMB expansion when it really is enterprise displacement.
What makes agentic AI distinct from AI from two years ago is that today’s AI models are now decision makers, not just glorified summarizers. Agents decide what to search for and how to perform a search. Moreover, they can retrieve large amounts of contextual information, like entire documents, which provides additional nuance that RAG typically misses.
For GTM teams, that raises the bar for context.
In DataHub's 2026 State of Context Management report, 77% of IT and data leaders surveyed said RAG alone is insufficient for accurate, reliable AI deployments in production across departments. The same report found that 83% agree that agentic AI cannot reach production value without a context platform, while 66% report AI models generating biased or misleading insights because their data infrastructure lacks sufficient context.
Read charitably, retrieval is not the same thing as understanding the business.
Why RAG Was The Obvious First Move
The original RAG paper made the case cleanly: models carry knowledge in their parameters, but that knowledge is hard to update and hard to source. Retrieval lets a model consult external memory.
For the first wave of GTM AI, that was exactly what teams needed.
Put the company docs somewhere. Chunk them. Embed them. Search for the chunks most similar to the prompt. Add those chunks to the model call. Generate.
That architecture made a lot of early AI work possible, but complex applications demanded more context.
OpenAI's 2023 DevDay reflected this. GPT-4 Turbo introduced a 128K context window, and OpenAI also announced Retrieval in the Assistants API so developers did not have to build the whole retrieval stack themselves.
While GPT-4 Turbo unlocked the ability to put enough information into a prompt, but retrieval is more than dumping documents into a large context window.
Where Generic RAG Breaks In GTM
GTM knowledge is not a pile of facts. It is a set of relationships.
"We sell to CFOs" is barely useful. What matters is that CFOs at usage-based infrastructure companies care about margin predictability before a fundraise. The best proof point is the customer who kept pipeline quality flat while reducing cost per meeting.
That kind of knowledge lives at the intersection of product, persona, segment, motion, trigger, competitor, objection, proof, and deal stage.
Generic RAG flattens those relationships into chunks.
Sometimes that works for simple questions, like if someone asks for a refund policy.
But if a rep asks, "How should I sell hosted to a technical buyer who already uses our open-source project?", semantic similarity can become a trap. A document about open-source adoption may be very close to the query. It may also be the wrong strategic answer. The buyer already believes in the open-source project. The hosted pitch needs to lead with governance, security review, admin control, and migration risk.
In the last example, the retrieval was precise, but the guidance was wrong.
Research has been naming this failure mode for a while. The "Seven Failure Points" RAG paper describes RAG systems as vulnerable to both information retrieval limits and LLM limits, with robustness evolving only through operation. "Lost in the Middle" showed that even when relevant information is present in long context, models can use it poorly depending on where it appears. Anthropic's Contextual Retrieval work points to a more basic issue: traditional RAG often strips context away when chunks are encoded, which can cause failed retrieval in the first place.
The practical GTM version is simple: the model finds words that are close. Your best rep knows what the question is really asking.
The Maintenance Problem Is The Hidden Cost
The visible failure is a bad answer, but there is also a hidden failure: the work required to prevent the next one.
That is the trap in many DIY RAG and point-agent systems. Each workflow has its own prompt, its own context block, its own assumptions, its own stale copy of the strategy. When positioning changes, the team has to hunt through agents, workflows, Claude projects, n8n nodes, slide decks, and personal context folders.
When every agent carries a different copy of the business, the company stops compounding what it learns. Marketing updates the positioning, but sales keeps using the old talk track. RevOps changes the qualification logic, but the outbound workflow still routes leads against last quarter's ICP.
The system gets busier and less coherent.
Agents Need A Map, Not A Memory Drawer
Code got to this pattern first.
Claude Code changed coding because it can inspect a codebase, read files, edit files, run commands, and revise based on the result. It works because code already has structure. Files import files. Functions call functions. Tests fail. The agent has a world it can traverse.
GTM does not come with that world.
There is no import graph for positioning. There is no compiler error when the outbound sequence uses the wrong competitor framing. There is no failing test when a new product launch makes last month's qualification rule stale.
This is why agentic GTM needs a different context layer.
It needs a structured map of what the company knows: products, personas, segments, competitors, buying triggers, proof points, objections, motions, and the typed relationships between them. It needs to know that a proof point applies to one motion but not another. It needs to know that a competitor matters for enterprise displacement, but not for SMB education. It needs to know what changed last week.
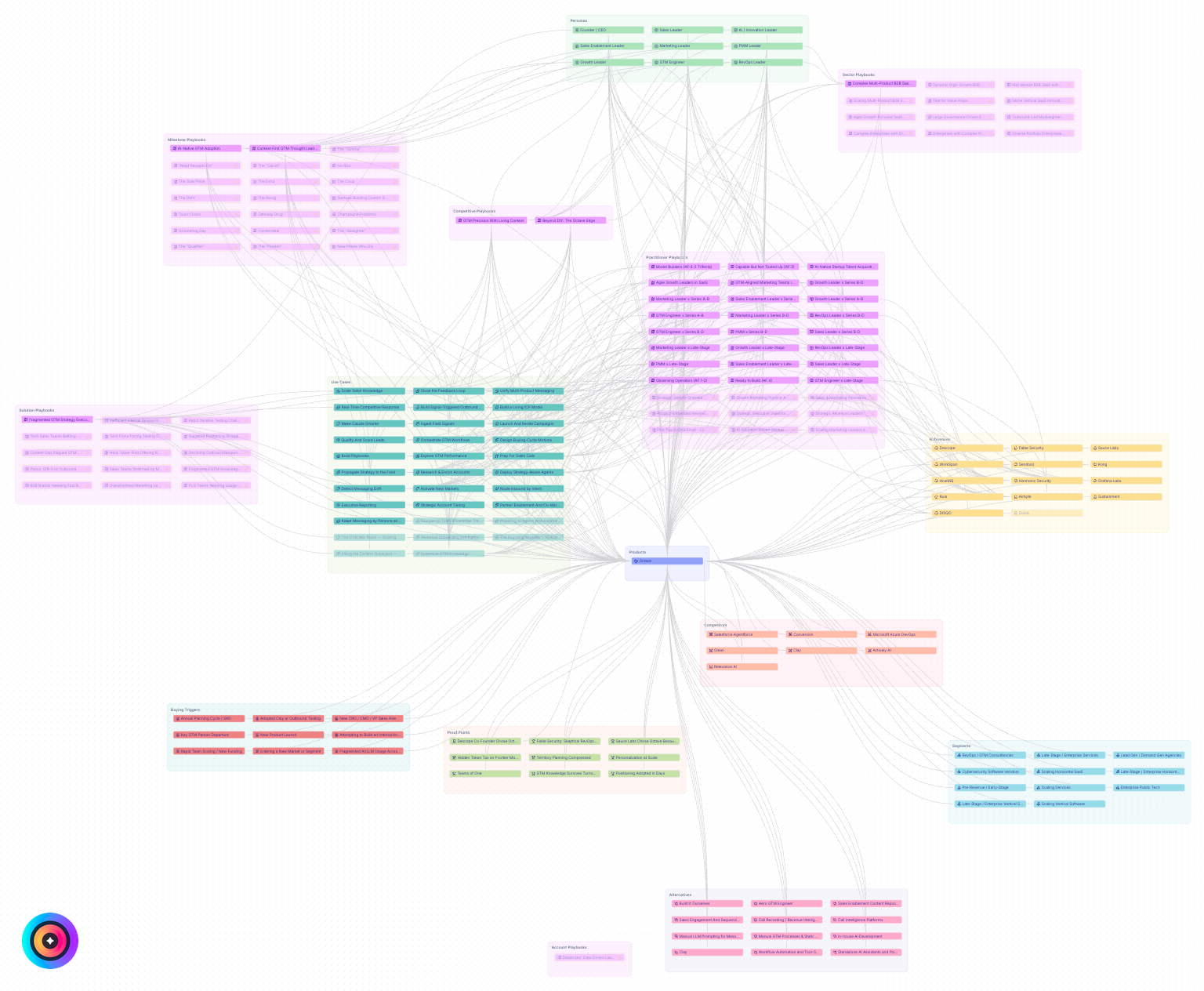
What Octave Changes
When you make AI do all the work of retrieving, reasoning, generating, it is bound to make mistakes.
The old way of doing RAG asks: "Which document chunk is most similar to this prompt?" But similarity is not always the same as relevant, and relevant information may still need to be reasoned with.
Octave asks a more useful question: "Which pieces of GTM strategy does this agent need to make the right decision?"
That distinction matters because Octave is not trying to be a better pile of docs.
Instead of retrieving a paragraph that says "our open-source project is flexible," an Octave agent can pull the current motion, target persona, buying trigger, relevant proof, and the objection to avoid.
The output changes from a generic answer to a situational one:
Question: How should I position hosted for a technical buyer already using open source?
Relevant motion: Convert open-source users to hosted enterprise
Persona: Platform engineering leader
Buying trigger: Security review and internal governance pressure
Do not lead with: Community adoption or developer flexibility
Lead with: Keep the developer workflow while removing operational burden
Proof to use: Enterprise migration story and admin-control proof point
Objection to prepare for: "We can host it ourselves"
Recommended action: Send migration-risk email, not generic product overview
Sam Gong, SVP of Marketing at Workspace, gives the strongest comparison:
"Octave gives you our point of view, not a search result. It knows how we position instead of just what exists in a document."
The first context layer helped AI find information.
The next one helps agents act from the company's point of view.
