A year ago, we could get more out of our agents by writing better prompts. Today, investing in better instructions no longer yields the gains it once did, because agents can walk on their own.
So what’s the next frontier to improve agent performance? Context.
There are 2 types of context a business needs for agent enablement. At Octave, we talk to many marketers who are figuring out how to use what we call “type 2 context,” which defines your GTM strategy.
Giving your agents good type 2 context is like handing them a map of your hometown, whereas prompting is like handing them directions for how to get from your house to the supermarket.
Definitions
Two types of context: (1) event-based and (2) strategic
Type 1 context is fact- or event-based. It’s a record of all the “happenings” in and around your business.
It includes first-party data in your systems of record, such as:
- Your CRM, with its deal history, interaction logs, and account notes
- Your data warehouse, with product telemetry and marketing data
- Your communication, in call recordings, emails, support channels
And third-party data, like:
- Enrichment sources (firmographic, technographic, etc.)
- News in your industry
- Competitive intel about your market
This data is structured and lives well in a database. It’s deterministic, always changing, and arrives through many sources.

Meaning can emerge from type 1 context. It can tell you what happened, but not necessarily why, what it means to your business, or what to do about it.
Next, there’s type 2 context, which is strategic or “opinion-based” context.
It uses your company’s GTM strategy to make type 1 context more usable, interpreting the patterns in your fact-based context so your agents can use it in a way that’s consistent with your business goals.
This includes elements such as:
- your ICP definition
- the names and pains of all of the personas and segments you sell to
- your products and services
- the use cases for your products
- your competitors and your competitive differentiation against each one
- your brand voice
- your positioning
- your sales plays
- your proof points and successful customers’ results
- typical objections, with your responses
- and more
It’s the reasoning behind who to target, what to say, and why your offering wins.
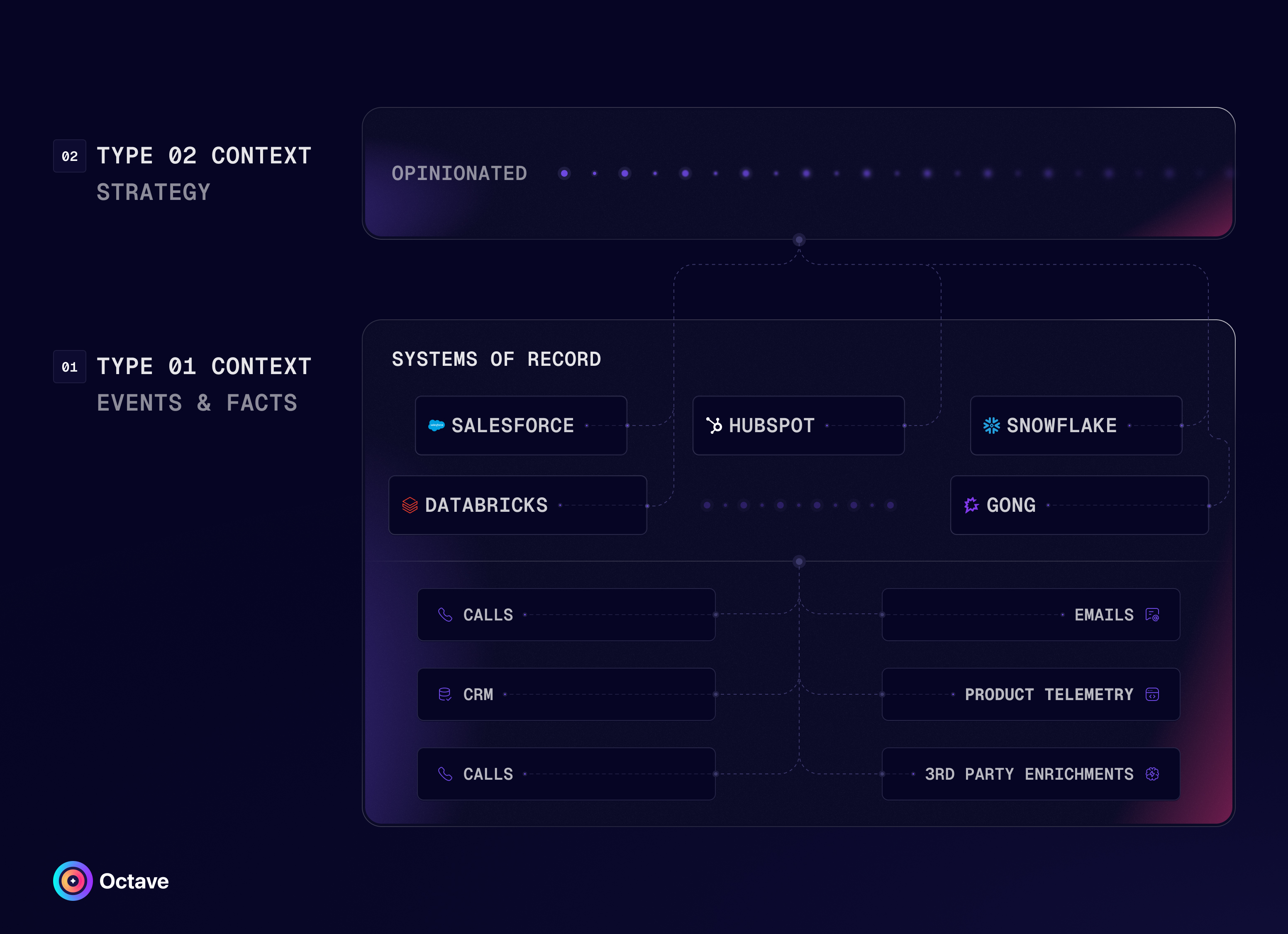
Compared to the chaos and volume of type 1 context, type 2 is a reasoned, sane, and concisely opinionated layer that guides an agent to make sense of source data — to understand the meaningful connections among events and facts through the lens of the business’s GTM strategy in real-time.
This is the “why, and what now” context that enables action.

For example, if you build an agent to qualify accounts or leads, your type 2 context will help the agent understand what your ICP is. The type 1 context will include the data and events used for qualification (firmographics, call recordings, emails exchanged, etc.).
Ideally, type 2 context describes the unique relationships between variations of entities: Which features and use cases map to which segments? Which objections does one of your personas typically bring up? Which ones do they never mention? This relational information helps you navigate a path more intelligently.
Another way to think about it:
🏙️ A city = Type 1 context
Type 1 context is like a dense city that never sleeps. It’s ever-changing, massive, and easy to get lost in — a composite of many cultures.
🧍Tourists = your agents
Tourists enter the city with different missions, like fetching a postcard from a souvenir store, finding the famous art museum, or trying the 10 best gelato spots.
🗺️ Map = Type 2 context
Instead of letting tourists loose in the city with no guidance—they might get lost or bring back the wrong souvenir—you give them a map. They use their judgment to navigate down the streets to the destination.

The best part is that one great map can be shared by all the tourists, getting them to many different places.
Unlike the city, a map is light enough for the tourists to hold in their hands. One type of context is vast and expansive, while the other is designed and curated, but together they allow visitors to accomplish what they came for.
Attributes of each type
How can you tell the difference between type 1 and type 2 context?
Both types of information we’re describing could appear in an .md file, right?
For example, you could ask Claude to qualify prospects based on a doc with:
- firmographic data and a call transcript (type 1), and
- an ICP definition at the top (type 2).
But these flavors of context are very different in nature. While they work side by side in an .md file, it starts getting more complicated when you roll this out across a full GTM organization. Type 2 context just does not cleanly fit into the same places that comfortably hold type 1.
Let’s look at some characteristics of type 2 context.
(a) Opinionated about patterns
Whereas type 1 context is an unbiased record of facts independent of your GTM strategy, type 2 context is purposefully biased toward your unique GTM strategy and shaped over time by your team's hard-won learnings and experiences. Its job is to be opinionated.
Patterns will, of course, emerge from the facts of type 1 context, but not all are necessarily relevant to your strategy. Meanwhile, type 2 is entirely concerned with patterns in the data that support or challenge the core GTM strategy and has opinions about them.
Strategic context also includes who you don’t target or what you don’t sell. This type of information would never exist in a type 1 data setting; there’s simply no place for it.
(b) Centralized
In order for type 2 context to work consistently, you need one source of it — a “latest version” in one tool. Multiple copies stored in multiple tools cause conflict and drift.
This is fundamentally different from type 1 context, which comes from many different sources.
We also believe it’s best to decouple type 2 context from type 1 by storing it in a purpose-built home (like Octave) instead of a type 1 system of record. Systems of record don’t provide the architecture needed to hold all the relationships between GTM entities, to self-learn, and to integrate many internal and external data sources into this architecture — more on this below.
(c) Changes are deliberate, less frequent, and aggregated
Deliberate:
- Changes to type 1 context happen to you. Someone downloads your app or visits your site, so that action gets recorded. Changes to type 2 context are, by definition, intentional to better reflect your strategy. An example of a large change to your type 2 context might be: adjusting your ICP definition from midsize services firms to enterprise services firms. A small example could be: “identify a new buying trigger.” Regardless of the size or type of change, your business consciously accepts it — like adding a new attraction to your map.
Less frequent than type 1 changes:
- The volume and frequency of changes to type 1 context are typically much higher than changes to type 2. For example, anytime someone signs up for a webinar, that’s a type 1 change. 800 webinar signups do not (necessarily) sway your GTM strategy, and even if it did, it would be a ratio of 1 change to 800.
Aggregated:
- Changes in type 2 context are aggregates of changes that happen in type 1 data. These aggregates may draw from more than one “source,” like your webinar signups and your ad click data and your CRM’s dealflow and a presentation about your product’s new feature release.
For example, maybe you hear of a new competitor popping up in deals, get intelligence about it from industry news, and see its presence in the third-party technographic data of a prospect list.
(d) Mediating
When you think about changes within type 1 context, you’ll notice that the rate and weight of changes differ from source to source. In one day, you might get 100 webinar signups in HubSpot, 300,000 product actions logged in Snowflake, and 1 closed deal that shifts your average ACV in Salesforce.
Your type 2 context should be able to absorb this chaos and produce a single clean interpretation — like the transmission in your car that takes the high RPM of your engine and converts it into a speed your wheels can actually turn.
So it would weigh all these inputs appropriately. It wouldn’t suggest making your ICP more SMB-focused just because 80% of signups for one of your webinars were from SMBs. But it might detect a trend across all these sources that your business may be finding traction in the SMB segment.
(e) Outsized impact
Type 2 context takes fewer tokens than type 1 context, yet it still helps your agents be more effective by telling them how to best use the data at hand. Put another way, it's how you get full value from the data you already pay for, and from the agents you're investing in.
(f) Relational
Type 2 context helps agents understand the unique combinations of entities in your go-to-market.
For example:
- Type 1 context tells you that: Acme Corp has 500 employees and is in Series C.
- Type 2 context tells you that: Series C SaaS companies [segments] with a new CRO [buying trigger] are your highest-converting segment, that they care about time-to-pipeline [pain], that your strongest proof point is the 58% cost-per-meeting reduction at a similar company [proof points and reference customers], and that the objection you’re most likely to hear is “we just hired BDRs to do this in-house” [objection]. Acme Corp would therefore be a perfect candidate for two of the five sales plays you’re running right now.
The second is actionable and helps you close deals by pulling out a specific slice of recommendations as a reaction to the type 1 context (firmographic data).
At Octave, these complex connections between GTM entities are held in a context graph.
Why type 2 can’t be in a CRM
Can't my CRM or data warehouse hold type 2 context?
Your systems of record all offer AI features now, including Salesforce, Gong, Snowflake, etc.
Can’t they hold your type 2 strategy, and keep it up to date by reading all the type 1 context?
After all, as the hub in a hub-and-spoke model, they plug into many outside sources of type 1 context (e.g., Salesforce AI being able to read call transcripts), so theoretically they would be able to learn from it.
Unfortunately, these systems of record are not built to capture type 2 strategy and lifecycle it because they don’t have the needed schemas, structures, and primitives.
We asked Octave’s sales leader what it would take to build a self-learning type 2 context engine in Salesforce (he was a VP there for 10 years). In short, it would take over 12 months, cost 1-2x your baseline CRM cost due to the sandboxes required for development, and you still wouldn’t have full self-learning capabilities or robust connections to all the type 1 data sources you need.
Why type 2 can’t be in git
Can’t my agents hold type 2 context? Why not just use markdown files in a git repo?
Let’s say you want Claude to write a targeted enterprise email campaign. You could store the strategy and the source data in a git repo. But it stops working when you go from a one-off project to the full activities of a GTM org over time.
Here’s why we don’t recommend it:
- Context outgrows the container: A GTM organization has exponential complexity — imagine that you’re planning three dozen campaign types, selling multiple products to multiple personas on multiple teams in 11 industries, and with people at every funnel stage.
- Hierarchy and consistency issues: You may have conflicts between instructions. You want agents to see the same patterns and react accordingly, rather than improvising from their own raw instructions.
- Drift: If your strategy changes (e.g., ICP definition now includes SMBs), then you’re hand-editing N projects. Or, your agents go out of date.
- Flat and not relational: Instructions and doc folders are flat. As we mentioned, at Octave, we organize type 2 context into a context graph that encodes complex relationships, supporting agent comprehension and token-efficient retrieval. While you could explain relationships in a file, it would get long and is prone to retrieval errors.
- Not enough self-learning: Your strategy layer should be thoughtfully updated as you learn about the market, like when deals close, customer calls reveal preferences, and competitors change. Instructions in an agent are unlikely to learn from what the recorded layer is telling you. Even if they’re capable of it, you still have the inconsistency issue from agent to agent.
We prefer that agents specialize in how to act on a task, rather than managing type 2 context, because it’s a very different job.
Put your agents to work
This is what we’re building at Octave: a platform purpose-built to turn your strategy into precise and always current type 2 context that every agent, workflow, and tool can rely on in real-time to execute smarter, more effective actions. It also lets you learn from type 1 context in an ongoing way, and ingest it intelligently for faster, cheaper, and more accurate agent responses.
Octave doesn’t replace your systems of record. But it learns from them and provides specialized human-in-the-loop workflows for critical, deliberate changes the business always requires. Update your strategy once, and every agent navigating by it updates too.
You’ve spent years and millions of dollars teaching your people your business. Now it’s time to do the same for agents, give them the map they need to understand your GTM strategy and start navigating your market.
